凡人,来感受一下组合索引的威力吧
大家好,我是飘渺!
相信各位在面试时,通常会被问到“什么是索引?” 而你肯定可以脱口而出:索引是提升查询速度的一种数据结构。而索引之所以能提升查询速度,在于它在插入时对数据进行了排序。
在实际业务中,我们会遇到很多复杂的场景,比如对多个列进行查询。这时,可能会要求用户创建多个列组成的索引,如列 a 和 b 创建的组合索引,但究竟是创建(a,b)的索引,还是(b,a)的索引,结果却是完全不同的。
今天,我们就来聊聊更贴近业务实战的组合索引,一起来感受一下组合索引的威力。(当然咯,文章中讲的索引指的是B+树索引,就是那个矮胖子啦)
组合索引
组合索引(Compound Index)是指由多个列所组合而成的 B+树索引,这和B+ 树索引的原理完全一样,只是单列索引是对一个列排序,现在是对多个列排序。
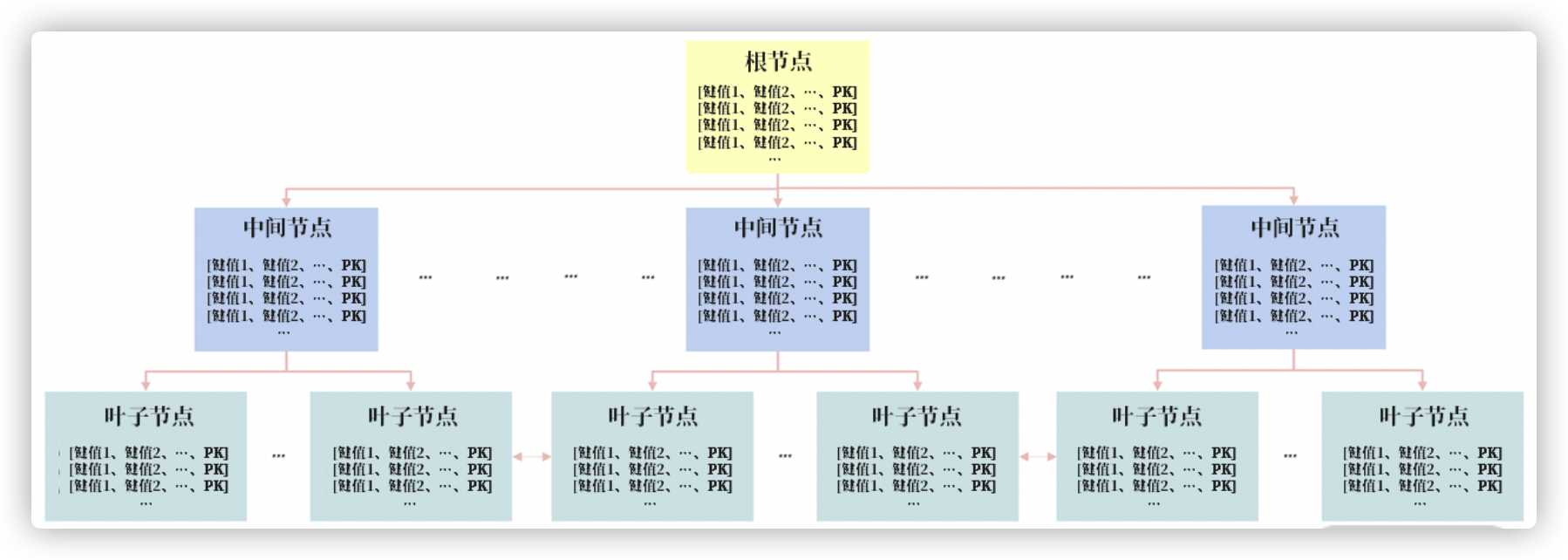
从上图可以看到,组合索引只是排序的键值从 1 个变成了多个,本质还是一颗 B+ 树索引。但是你一定要意识到(a,b)和(b,a)这样的组合索引,其排序结果是完全不一样的。
假如有如下一张表test,给其创建了一个组合索引union_index。
create table test
(
id int auto_increment primary key,
name varchar(50) null,
workcode varchar(50) null,
age int null
);
create index union_index on test (name, workcode);那对于组合索引(name,workcode)来说,因为它对name,workcode做了排序,所以它可以对下面两个查询进行优化
select * from test where name = 'zhang' ;
select * from test where name = 'zhang' and workcode='20190169';值得注意的是,where后查询列name 和workcode的顺序无关,即使写成where workcode = '20190169' and name ='zhang'仍然可以使用组合索引(name,workcode)。

但是下面的sql无法使用组合索引(name,workcode),因为(name,workcode)排序并不能推出(workcode,name)排序。
select * from test where workcode='20190169';此外,同样由于索引(name,workcode)已排序,因此下面这条 SQL 依然可以使用组合索引(name,workcode),以此提升查询的效率:
select * from test where name = 'zhang' order by workcode;同样的原因,索引(name,workcode)排序不能得出(workcode,name)排序,因此下面的 SQL 无法使用组合索引(name,workcode):
select * from test where workcode = '20190169' order by name ;讲到这儿,你已经掌握了组合索引的基本内容,接下来我们就看一看怎么在业务实战中正确地设计组合索引?
业务索引设计实战
避免额外排序
在真实的业务场景中,你会遇到根据某个列进行查询,然后按照时间排序的方式逆序展示。
比如在微博业务中,用户的微博展示的就是根据用户 ID 查询出用户订阅的微博,然后根据时间逆序展示;又比如在电商业务中,用户订单详情页就是根据用户 ID 查询出用户的订单数据,然后根据购买时间进行逆序展示。
接着我们看一下我们线上一个真实的商机表,已经对字段做了简化,只保留几个关键字段,同时为了方便测试,直接初始化了70多万的数据。
CREATE TABLE t_opp_base
(
id int primary key auto_increment,
opp_code varchar(50) NOT NULL, -- 商机编码
opp_name varchar(200) NOT NULL,
principal_user varchar(50) NOT NULL, -- 责任人
opp_status char(1) NOT NULL,
opp_amount decimal(15, 2) NOT NULL,
opp_date date NOT NULL,
opp_priority char(15) NOT NULL,
remark varchar(79) NOT NULL,
KEY `idx_opp_code` (opp_code),
KEY `idx_principal_user` (principal_user)
);其中:
- 字段 id 是 INT 类型的主键;
- 字段 opp_code,principal_user 由于查询的场景比较多,所以添加了单字段索引
- 字段 opp_date、opp_status、opp_amount、opp_priority 用于商机的基本详情,分别表示商机时间、当前商机的状态、商机的总价值、商机的优先级。
在有了上述商机表后,当用户查看javadaily负责的商机信息,并且需要根据商机时间排序查询时,可通过下面的 SQL:
select * from t_opp_base where principal_user = 'javadaily' order by opp_date DESC但由于上述表结构的索引设计时,索引 idx_principal_user 仅对列 principal_user 排序,因此在取出用户的数据后,还需要一次额外的排序才能得到结果,可查看执行计划 EXPLAIN 确认:
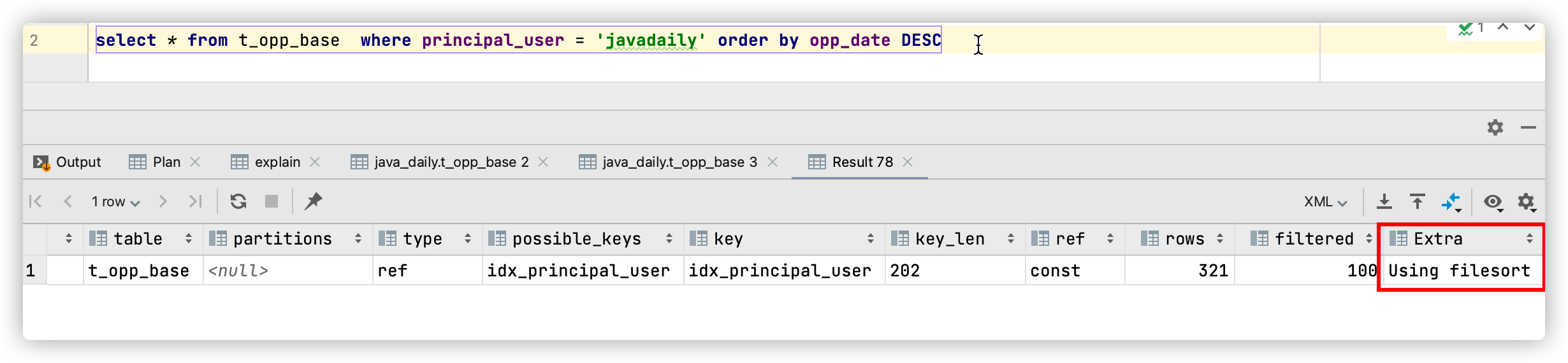
通过上面的执行计划可以看出,SQL 语句的确可以使用索引 idx_principal_user,但在 Extra 列中显示的 Using filesort,表示还需要一次额外的排序才能得到最终的结果。
由于已对列 principal_user 创建索引,因此上述 SQL 语句并不会执行得特别慢,但是在高并发的情况下,每次 SQL 执行都需要排序就会对业务的性能产生非常明显的影响,比如 CPU 负载变高,QPS 降低。
要解决这个问题,最好的方法是:在取出结果时已经根据字段 opp_date 排序,这样就不用额外的排序了。
所以,我们在表t_opp_base上创建一个新的组合索引,idx_principal_oppdate,对字段(principal_user,opp_date)进行索引。
create index idx_principal_oppdate
on t_opp_base (principal_user,opp_date);这是再执行之前的sql,根据时间展示责任人负责的商机项目,其执行计划为:

这样我们就消除了Using filesort,提高了执行效率。
索引覆盖,避免回表
基础概念:
SQL需要二级索引查询得到主键值,然后再根据主键值搜索主键索引,最后定位到完整的数据。这一过程叫 回表。
但是由于二级组合索引的叶子节点,包含索引键值和主键值,若查询的字段在二级索引的叶子节点中,则可直接返回结果,无需回表。这种通过组合索引避免回表的优化技术也称为 索引覆盖(Covering Index)。
比如有下面一条SQL:
select principal_user,opp_date,opp_amount from t_opp_base where principal_user = 'javadaily' ;查看其执行计划:
-> Index lookup on t_opp_base using idx_principal_oppdate (principal_user='javadaily') (cost=312.51 rows=321) (actual time=0.452..0.908 rows=321 loops=1)它的执行计划显示使用了之前创建的组合索引idx_principal_user,但是,由于组合索引的叶子节点只包含(principal_user,opp_date,id),没有字段 opp_amount 的值,所以需要通过 id 回表找到对应的 opp_amount。
执行计划中显示执行成本cost为312.51。(cost=312.51 表示的就是这条 SQL 当前的执行成本。不用关心 cost 的具体单位,你只需明白cost 越小,开销越小,执行速度越快。)
如果想要避免回表,可以通过索引覆盖技术,创建(principal_user,opp_date,opp_amount)的组合索引,如:
alter table t_opp_base add index
idx_principal_oppdate_amount(principal_user,opp_date,opp_amount);再次查看执行计划:
-> Index lookup on t_opp_base using idx_principal_oppdate_amount (principal_user='javadaily') (cost=41.52 rows=321) (actual time=0.149..0.337 rows=321 loops=1)执行成本有明显的下降,从312.51降到了41.52,执行效率大大提高。
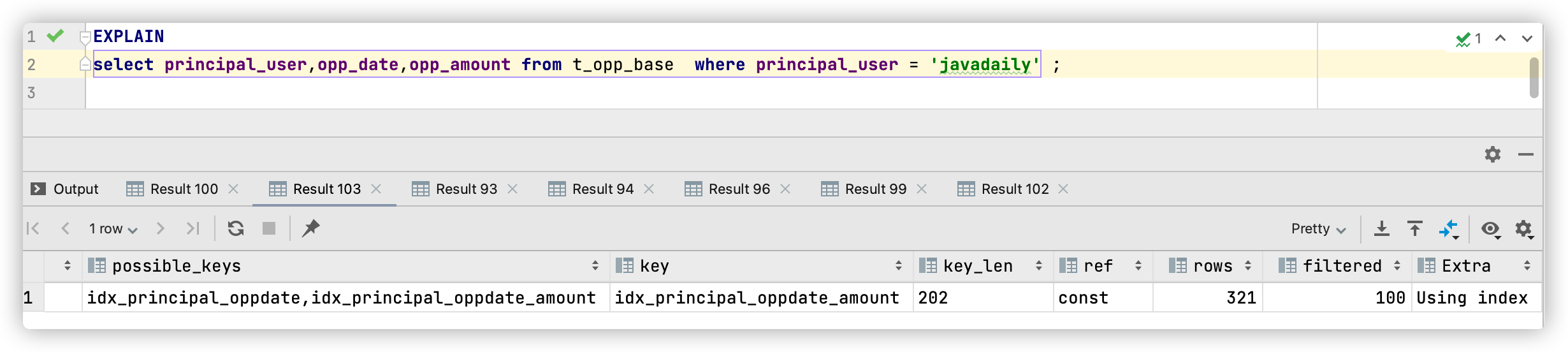
可以看到执行计划选择了idx_principal_oppdate_amount索引,同时Extra列显示为 Using index,这就表示使用了覆盖索引技术。
上面这条SQL一共返回321条记录,这意味着在未使用索引覆盖技术前,这条 SQL 需要总共回表 321 次, 每次从二级索引读取到数据,就需要通过主键去获取字段 opp_amount。在使用索引覆盖技术后,无需回表,减少了 321次的回表开销,这就是为什么执行成本会减少这么多的原因。
接下来我们再看看这条SQL
select principal_user,sum(opp_amount) from t_opp_base group by principal_user;这条SQL根据商机责任人分组汇总,找出每个责任人负责的商机价值总额,对责任人进行考核。
为了让大家直观感受一下索引覆盖的威力,我先删掉之前创建的索引idx_principal_oppdate_amount
ALTER TABLE t_opp_base
drop INDEX idx_principal_oppdate_amount;查看其执行计划
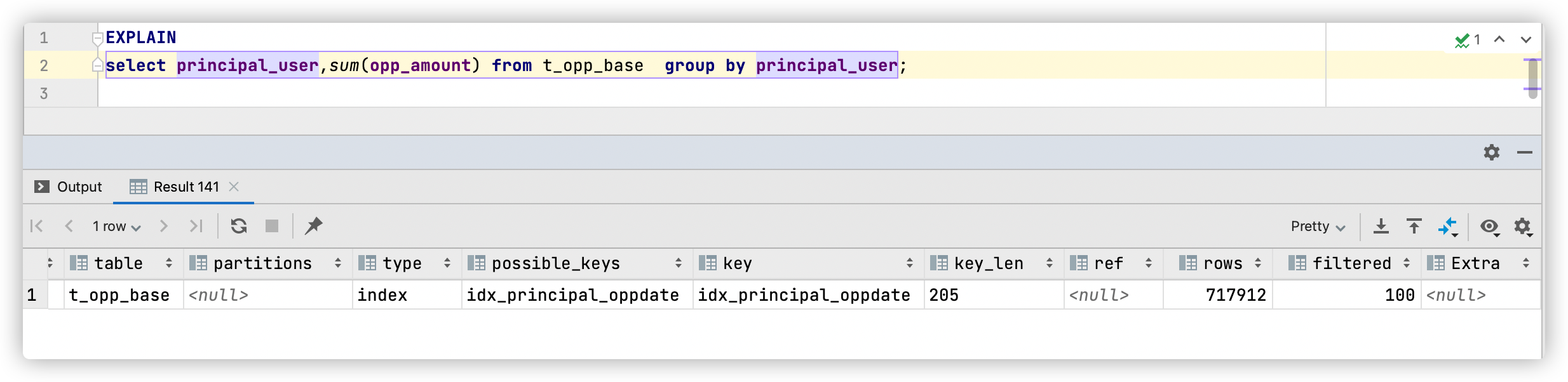
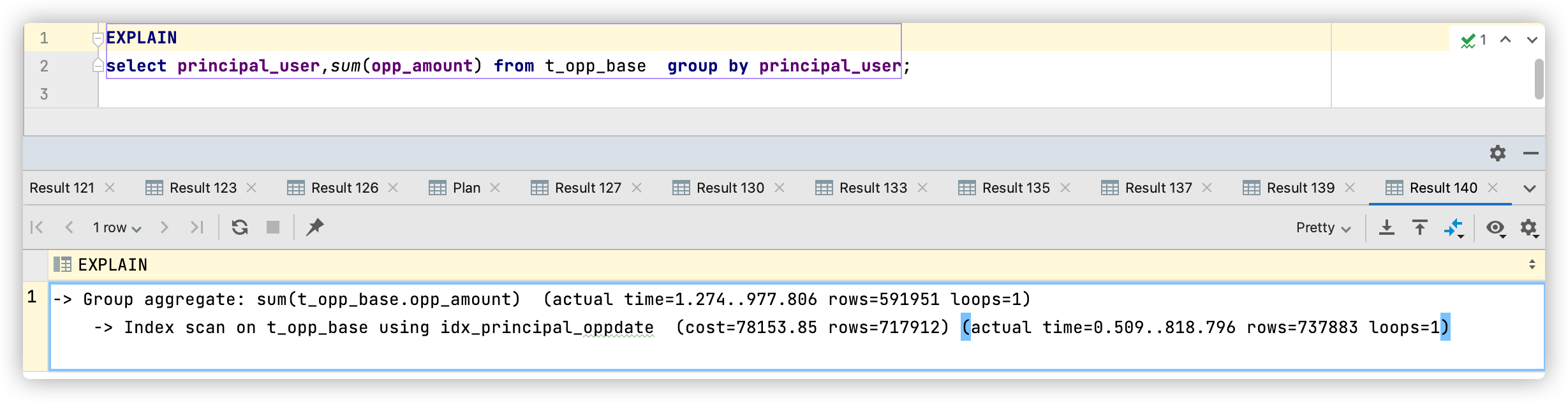
可以看到,这条 SQL 优化选择了索引 idx_principal_oppdate,但由于该索引没有包含字段opp_amount,因此需要回表,根据 rows 预估出大约要回表 717912 次。同时也可以看到执行成本为76850.31,执行时间为10.9秒。
然后我们再次加上组合索引idx_principal_oppdate_amount
alter table t_opp_base add index
idx_principal_oppdate_amount(principal_user,opp_date,opp_amount);再次查看执行计划
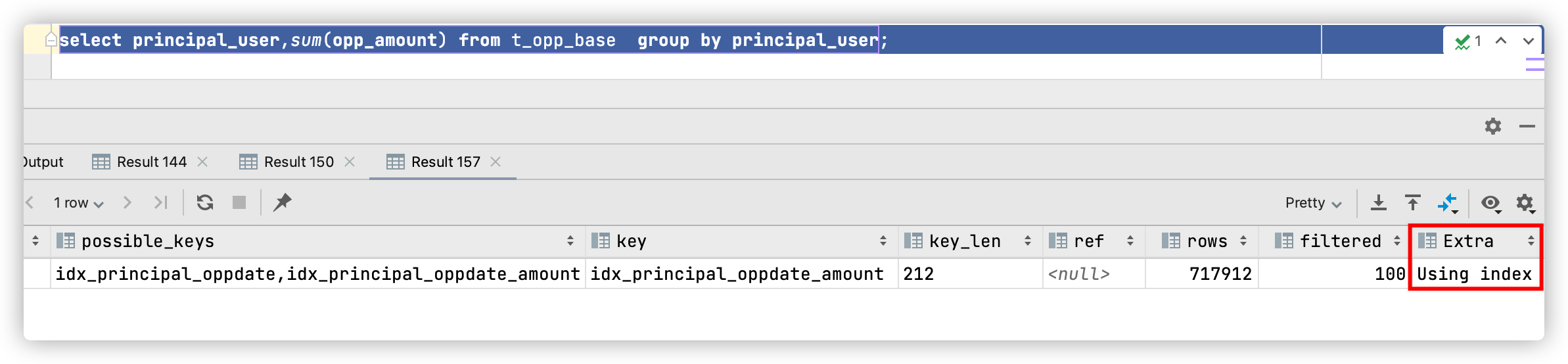
可以看到,这次的执行计划提升使用了组合索引 idx_principal_oppdate_amount,并且通过Using index 的提示,表示使用了索引覆盖技术。同时执行时间为1.74s,SQL性能大大提升。
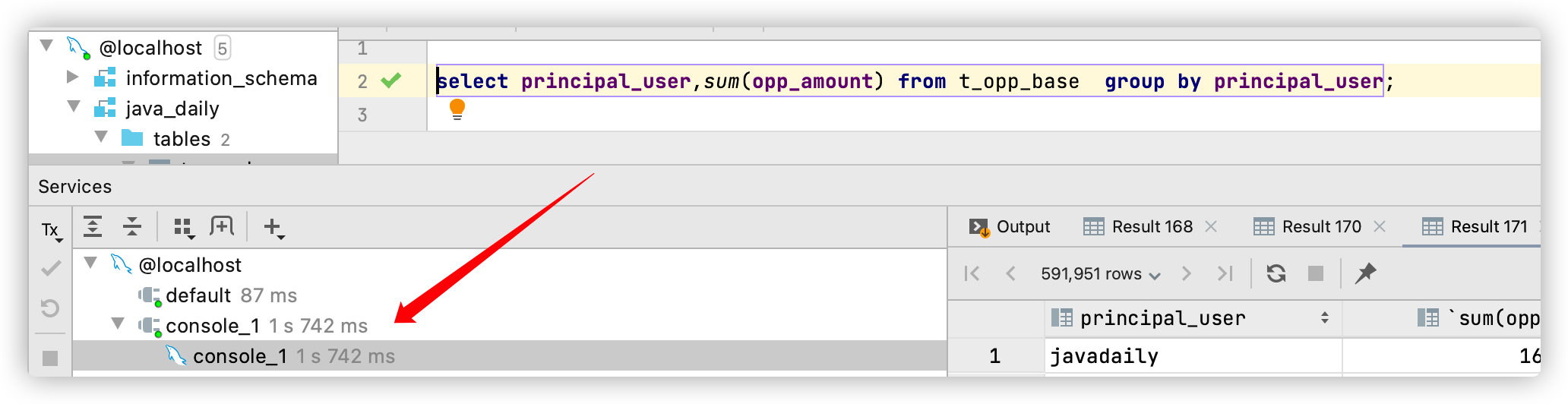
这就是索引覆盖技术的威力,而且这还只是基于 t_opp_base 表总共 70 万条记录。若表 t_opp_base 的记录数越多,需要回表的次数也就越多,通过索引覆盖技术性能的提升也就越明显。
小结
组合索引也是一颗 B+ 树,只是索引的列由多个组成,组合索引既可以是主键索引,也可以是二级索引。组合索引主要有以下三个优势:
覆盖多个查询条件,如(a,b)索引可以覆盖查询 a = ? 或者 a = ? and b = ?;
避免 SQL 的额外排序,提升 SQL 性能,如
WHERE a = ? ORDER BY b这样的查询条件;利用组合索引包含多个列的特性,可以实现索引覆盖技术,提升 SQL 的查询性能,用好索引覆盖技术,性能提升 10 倍不是难事。