聊聊接口性能优化
大家好,我是飘渺。
我负责的系统到2021年初完成了功能上的建设,开始进入到推广阶段。随着推广的逐步深入,收到了很多好评的同时也收到了很多对性能的吐槽。刚刚收到吐槽的时候,我们的心情是这样的:

当越来越多对性能的吐槽反馈到我们这里的时候,我们意识到,接口性能的问题的优先级必须提高了。然后我们就跟踪了1周的接口性能监控,这个时候我们的心情是这样的:

有20多个慢接口,5个接口响应时间超过5s,1个超过10s,其余的都在2s以上,稳定性不足99.8%。作为一个优秀的后端程序员,这个数据肯定是不能忍的,我们马上就进入了漫长的接口优化之路。本文就是对我们漫长工作历程的一个总结。
正文开始!
哪些问题会引起接口性能问题?
这个问题的答案非常多,需要根据自己的业务场景具体分析。这里做一个不完全的总结:
- 数据库慢查询
- 深度分页问题
- 未加索引
- 索引失效
- join过多
- 子查询过多
- in中的值太多
- 单纯的数据量过大
- 业务逻辑复杂
- 循环调用
- 顺序调用
- 线程池设计不合理
- 锁设计不合理
- 机器问题(fullGC,机器重启,线程打满)
问题解决
1、慢查询(基于mysql)
1.1 深度分页
所谓的深度分页问题,涉及到mysql分页的原理。通常情况下,mysql的分页是这样写的:
select name,code from student limit 100,20含义当然就是从student表里查100到120这20条数据,mysql会把前120条数据都查出来,抛弃前100条,返回20条。当分页所以深度不大的时候当然没问题,随着分页的深入,sql可能会变成这样:
select name,code from student limit 1000000,20这个时候,mysql会查出来1000020条数据,抛弃1000000条,如此大的数据量,速度一定快不起来。那如何解决呢?一般情况下,最好的方式是增加一个条件:
select name,code from student where id>1000000 limit 20这样,mysql会走主键索引,直接连接到1000000处,然后查出来20条数据。但是这个方式需要接口的调用方配合改造,把上次查询出来的最大id以参数的方式传给接口提供方,会有沟通成本(调用方:老子不改!)。
1.2 未加索引
这个是最容易解决的问题,我们可以通过
show create table xxxx(表名)查看某张表的索引。具体加索引的语句网上太多了,不再赘述。不过顺便提一嘴,加索引之前,需要考虑一下这个索引是不是有必要加,如果加索引的字段区分度非常低,那即使加了索引也不会生效。另外,加索引的alter操作,可能引起锁表,执行sql的时候一定要在低峰期(血泪史!!!!)
1.3 索引失效
这个是慢查询最不好分析的情况,虽然mysql提供了explain来评估某个sql的查询性能,其中就有使用的索引。但是为啥索引会失效呢?mysql却不会告诉咱,需要咱自己分析。 大体上,可能引起索引失效的原因有这几个(可能不完全):
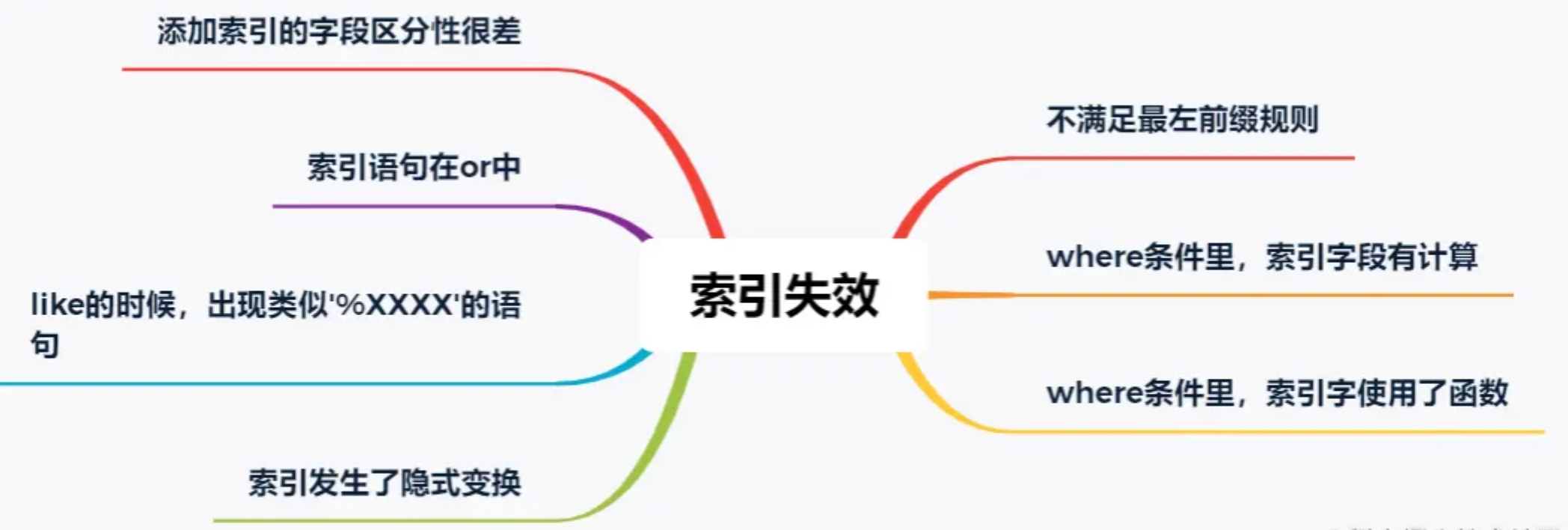
需要特别提出的是,关于字段区分性很差的情况,在加索引的时候就应该进行评估。如果区分性很差,这个索引根本就没必要加。区分性很差是什么意思呢,举几个例子,比如:
- 某个字段只可能有3个值,那这个字段的索引区分度就很低。
- 再比如,某个字段大量为空,只有少量有值;
- 再比如,某个字段值非常集中,90%都是1,剩下10%可能是2,3,4….
进一步的,那如果不符合上面所有的索引失效的情况,但是mysql还是不使用对应的索引,是为啥呢?这个跟mysql的sql优化有关,mysql会在sql优化的时候自己选择合适的索引,很可能是mysql自己的选择算法算出来使用这个索引不会提升性能,所以就放弃了。这种情况,可以使用force index 关键字强制使用索引(建议修改前先实验一下,是不是真的会提升查询效率):
select name,code from student force index(XXXXXX) where name = '天才' 其中xxxx是索引名。
1.4 join过多 or 子查询过多
我把join过多 和子查询过多放在一起说了。一般来说,不建议使用子查询,可以把子查询改成join来优化。同时,join关联的表也不宜过多,一般来说2-3张表还是合适的。具体关联几张表比较安全是需要具体问题具体分析的,如果各个表的数据量都很少,几百条几千条,那么关联的表的可以适当多一些,反之则需要少一些。
另外需要提到的是,在大多数情况下join是在内存里做的,如果匹配的量比较小,或者join_buffer设置的比较大,速度也不会很慢。但是,当join的数据量比较大的时候,mysql会采用在硬盘上创建临时表的方式进行多张表的关联匹配,这种显然效率就极低,本来磁盘的IO就不快,还要关联。
一般遇到这种情况的时候就建议从代码层面进行拆分,在业务层先查询一张表的数据,然后以关联字段作为条件查询关联表形成map,然后在业务层进行数据的拼装。一般来说,索引建立正确的话,会比join快很多,毕竟内存里拼接数据要比网络传输和硬盘IO快得多。
1.5 in的元素过多
这种问题,如果只看代码的话不太容易排查,最好结合监控和数据库日志一起分析。如果一个查询有in,in的条件加了合适的索引,这个时候的sql还是比较慢就可以高度怀疑是in的元素过多。一旦排查出来是这个问题,解决起来也比较容易,不过是把元素分个组,每组查一次。想再快的话,可以再引入多线程。
进一步的,如果in的元素量大到一定程度还是快不起来,这种最好还是有个限制
select id from student where id in (1,2,3 ...... 1000) limit 200当然了,最好是在代码层面做个限制
if (ids.size() > 200) {
throw new Exception("单次查询数据量不能超过200");
}1.6 单纯的数据量过大
这种问题,单纯代码的修修补补一般就解决不了了,需要变动整个的数据存储架构。或者是对底层mysql分表或分库+分表;或者就是直接变更底层数据库,把mysql转换成专门为处理大数据设计的数据库。这种工作是个系统工程,需要严密的调研、方案设计、方案评审、性能评估、开发、测试、联调,同时需要设计严密的数据迁移方案、回滚方案、降级措施、故障处理预案。除了以上团队内部的工作,还可能有跨系统沟通的工作,毕竟做了重大变更,下游系统的调用接口的方式有可能会需要变化。
出于篇幅的考虑,这个不再展开了,笔者有幸完整参与了一次亿级别数据量的数据库分表工作,对整个过程的复杂性深有体会,后续有机会也会分享出来。
2、业务逻辑复杂
2.1 循环调用
这种情况,一般都循环调用同一段代码,每次循环的逻辑一致,前后不关联。比如说,我们要初始化一个列表,预置12个月的数据给前端:
List<Model> list = new ArrayList<>();
for(int i = 0 ; i < 12 ; i ++) {
Model model = calOneMonthData(i); // 计算某个月的数据,逻辑比较复杂,难以批量计算,效率也无法很高
list.add(model);
}这种显然每个月的数据计算相互都是独立的,我们完全可以采用多线程方式进行:
// 建立一个线程池,注意要放在外面,不要每次执行代码就建立一个,具体线程池的使用就不展开了
public static ExecutorService commonThreadPool = new ThreadPoolExecutor(5, 5, 300L,
TimeUnit.SECONDS, new LinkedBlockingQueue<>(10), commonThreadFactory, new ThreadPoolExecutor.DiscardPolicy());
// 开始多线程调用
List<Future<Model>> futures = new ArrayList<>();
for(int i = 0 ; i < 12 ; i ++) {
Future<Model> future = commonThreadPool.submit(() -> calOneMonthData(i););
futures.add(future);
}
// 获取结果
List<Model> list = new ArrayList<>();
try {
for (int i = 0 ; i < futures.size() ; i ++) {
list.add(futures.get(i).get());
}
} catch (Exception e) {
LOGGER.error("出现错误:", e);
}2.2 顺序调用
如果不是类似上面循环调用,而是一次次的顺序调用,而且调用之间没有结果上的依赖,那么也可以用多线程的方式进行,例如:
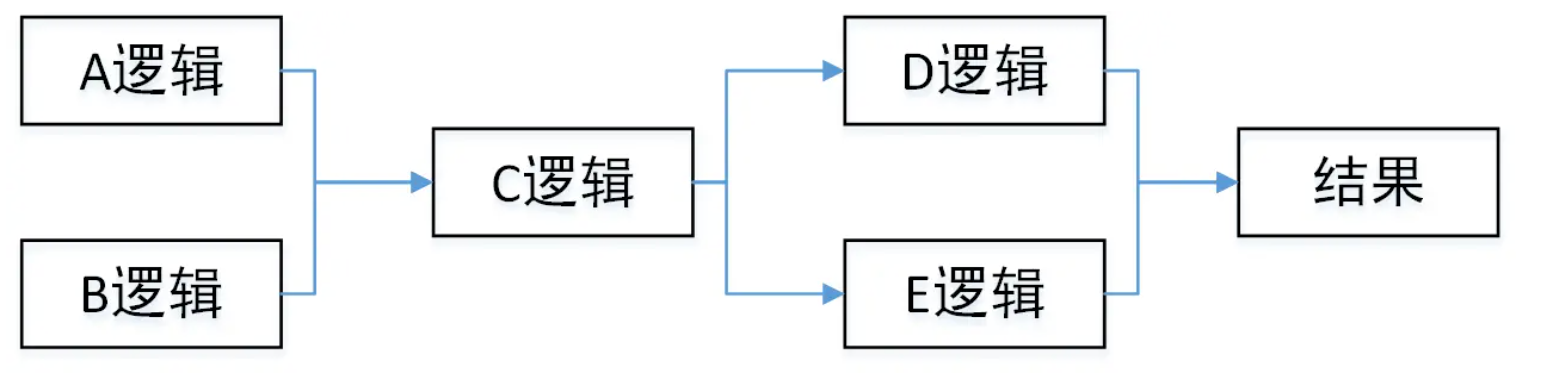
代码上看:
A a = doA();
B b = doB();
C c = doC(a, b);
D d = doD(c);
E e = doE(c);
return doResult(d, e);那么可用CompletableFuture解决
CompletableFuture<A> futureA = CompletableFuture.supplyAsync(() -> doA());
CompletableFuture<B> futureB = CompletableFuture.supplyAsync(() -> doB());
CompletableFuture.allOf(futureA,futureB) // 等a b 两个任务都执行完成
C c = doC(futureA.join(), futureB.join());
CompletableFuture<D> futureD = CompletableFuture.supplyAsync(() -> doD(c));
CompletableFuture<E> futureE = CompletableFuture.supplyAsync(() -> doE(c));
CompletableFuture.allOf(futureD,futureE) // 等d e两个任务都执行完成
return doResult(futureD.join(),futureE.join());
这样A B 两个逻辑可以并行执行,D E两个逻辑可以并行执行,最大执行时间取决于哪个逻辑更慢。
3、线程池设计不合理
有的时候,即使我们使用了线程池让任务并行处理,接口的执行效率仍然不够快,这种情况可能是怎么回事呢?
这种情况首先应该怀疑是不是线程池设计的不合理。我觉得这里有必要回顾一下线程池的三个重要参数:核心线程数、最大线程数、等待队列。这三个参数是怎么打配合的呢?当线程池创建的时候,如果不预热线程池,则线程池中线程为0。当有任务提交到线程池,则开始创建核心线程。
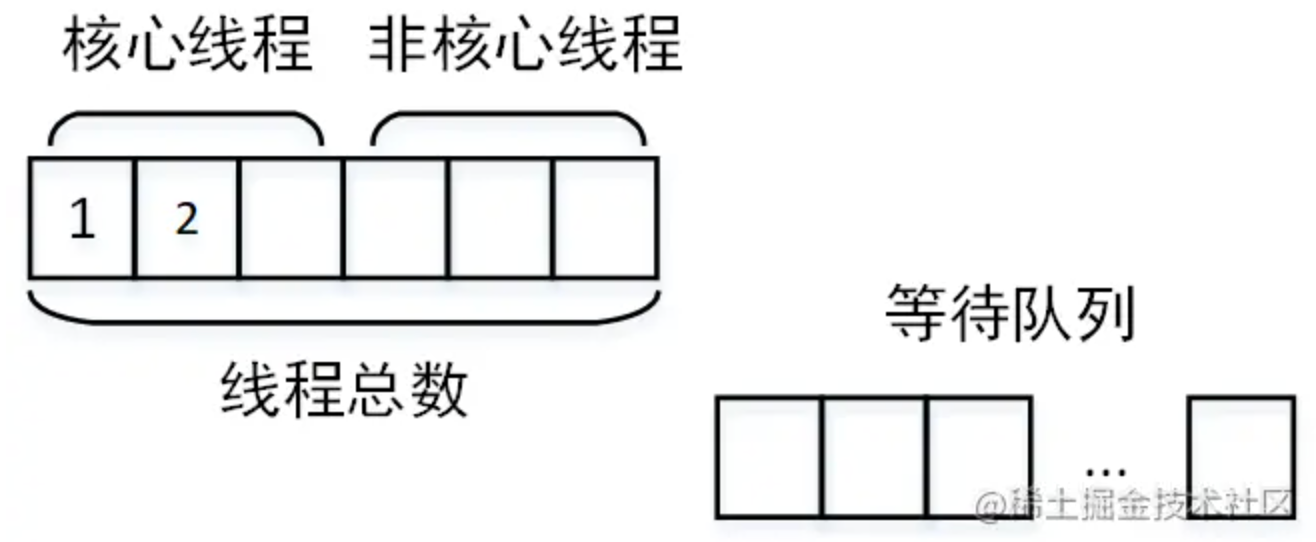
当核心线程全部被占满,如果再有任务到达,则让任务进入等待队列开始等待。
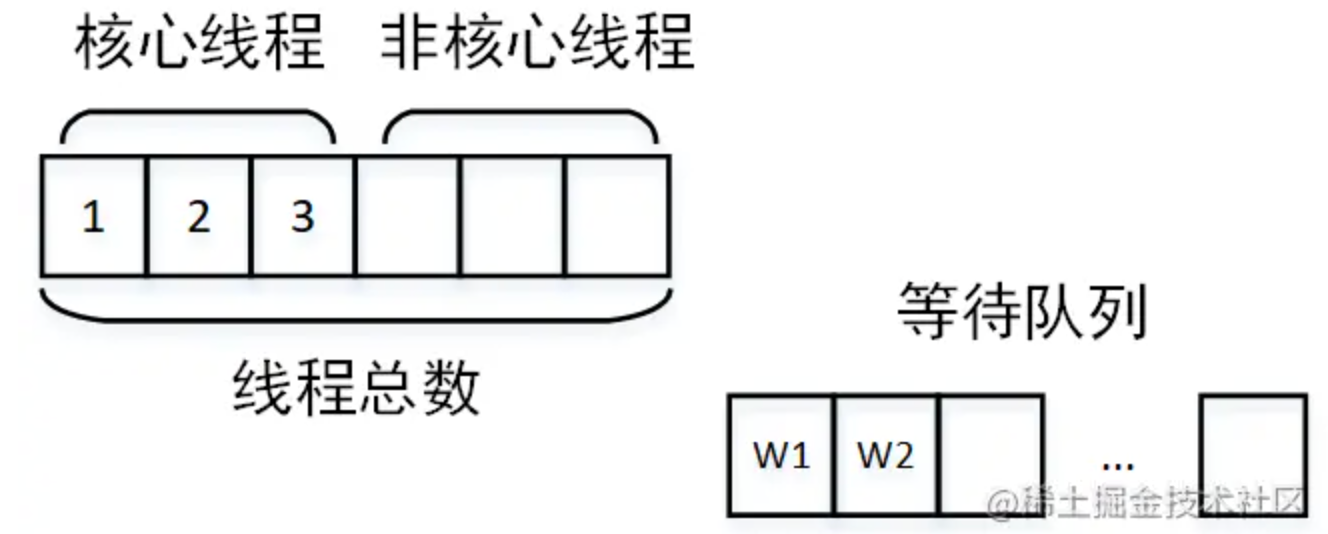
如果队列也被占满,则开始创建非核心线程运行。
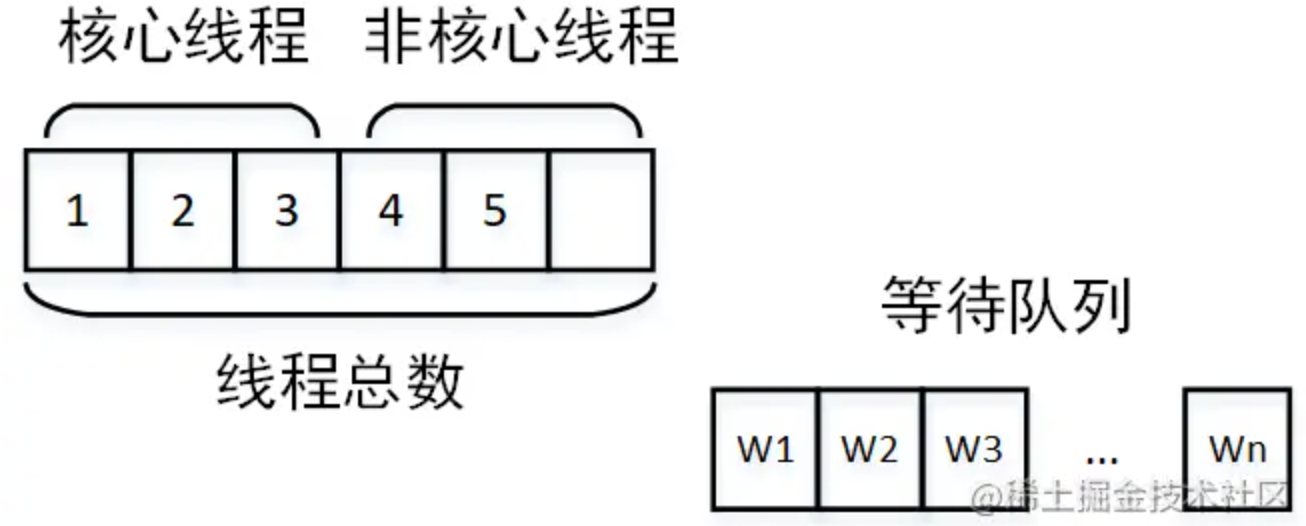
如果线程总数达到最大线程数,还是有任务到达,则开始根据线程池抛弃规则开始抛弃。
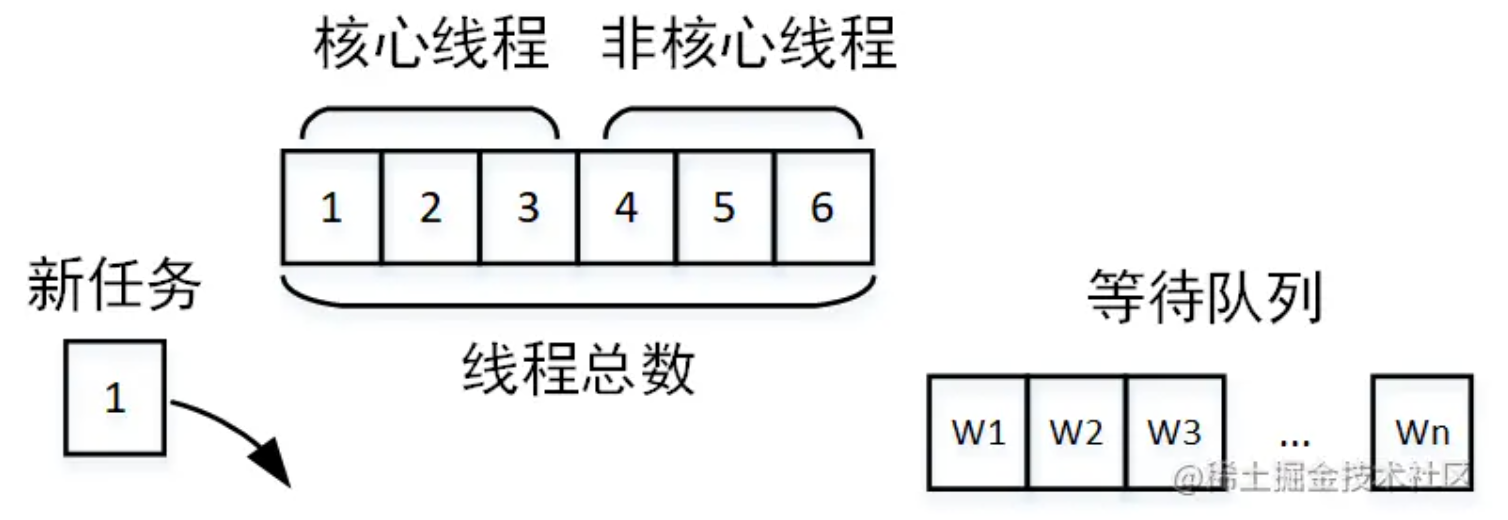
那么这个运行原理与接口运行时间有什么关系呢?
- 核心线程设置过小:核心线程设置过小则没有达到并行的效果
- 线程池公用,别的业务的任务执行时间太长,占用了核心线程,另一个业务的任务到达就直接进入了等待队列
- 任务太多,以至于占满了线程池,大量任务在队列中等待
在排查的时候,只要找到了问题出现的原因,那么解决方式也就清楚了,无非就是调整线程池参数,按照业务拆分线程池等等。
4、锁设计不合理
锁设计不合理一般有两种:锁类型使用不合理 or 锁过粗。
锁类型使用不合理的典型场景就是读写锁。也就是说,读是可以共享的,但是读的时候不能对共享变量写;而在写的时候,读写都不能进行。在可以加读写锁的时候,如果我们加成了互斥锁,那么在读远远多于写的场景下,效率会极大降低。
锁过粗则是另一种常见的锁设计不合理的情况,如果我们把锁包裹的范围过大,则加锁时间会过长,例如:
public synchronized void doSome() {
File f = calData();
uploadToS3(f);
sendSuccessMessage();
}这块逻辑一共处理了三部分,计算、上传结果、发送消息。显然上传结果和发送消息是完全可以不加锁的,因为这个跟共享变量根本不沾边。因此完全可以改成:
public void doSome() {
File f = null;
synchronized(this) {
f = calData();
}
uploadToS3(f);
sendSuccessMessage();
}5、机器问题(fullGC,机器重启,线程打满)
造成这个问题的原因非常多,笔者就遇到了定时任务过大引起fullGC,代码存在线程泄露引起RSS内存占用过高进而引起机器重启等待诸多原因。需要结合各种监控和具体场景具体分析,进而进行大事务拆分、重新规划线程池等等工作
6、万金油解决方式
万金油这个形容词是从我们单位某位老师那里学来的,但是笔者觉得非常贴切。这些万金油解决方式往往能解决大部分的接口缓慢的问题,而且也往往是我们解决接口效率问题的最终解决方案。当我们实在是没有办法排查出问题,或者实在是没有优化空间的时候,可以尝试这种万金油的方式。
6.1 缓存
缓存是一种空间换取时间的解决方案,是在高性能存储介质上(例如:内存、SSD硬盘等)存储一份数据备份。当有请求打到服务器的时候,优先从缓存中读取数据。如果读取不到,则再从硬盘或通过网络获取数据。由于内存或SSD相比硬盘或网络IO的效率高很多,则接口响应速度会变快非常多。缓存适合于应用在数据读远远大于数据写,且数据变化不频繁的场景中。从技术选型上看,有这些:
- 简单的
map guava等本地缓存工具包- 缓存中间件:
redis、tair或memcached
当然,memcached现在用的很少了,因为相比于redis他不占优势。tair则是阿里开发的一个分布式缓存中间件,他的优势是理论上可以在不停服的情况下,动态扩展存储容量,适用于大数据量缓存存储。相比于单机redis缓存当然有优势,而他与可扩展Redis集群的对比则需要进一步调研。
进一步的,当前缓存的模型一般都是key-value模型。如何设计key以提高缓存的命中率是个大学问,好的key设计和坏的key设计所提升的性能差别非常大。而且,key设计是没有一定之规的,需要结合具体的业务场景去分析。各个大公司分享出来的相关文章,缓存设计基本上是最大篇幅。
6.2 回调 or 反查
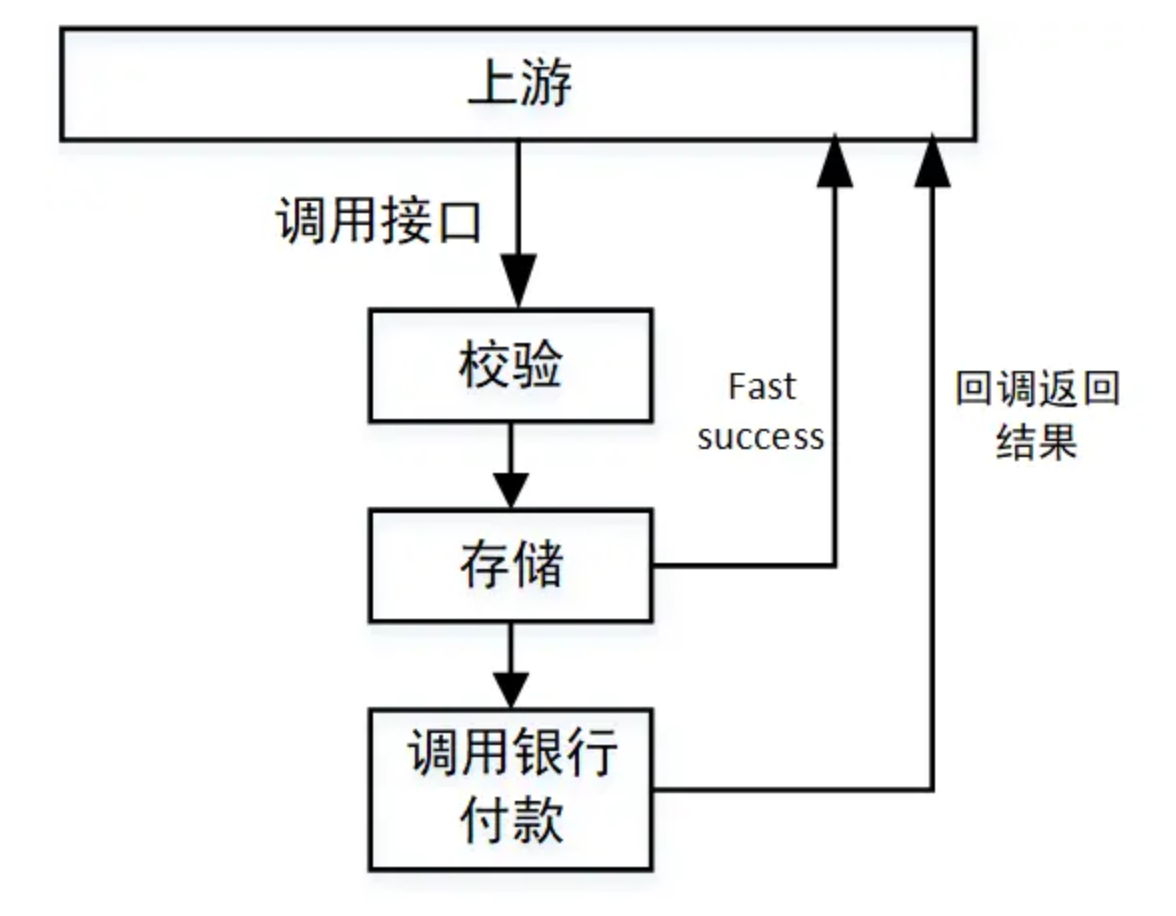
这种方式往往是业务上的解决方式,在订单或者付款系统中应用的比较多。举个例子:当我们付款的时候,需要调用一个专门的付款系统接口,该系统经过一系列验证、存储工作后还要调用银行接口以执行付款。由于付款这个动作要求十分严谨,银行侧接口执行可能比较缓慢,进而拖累整个付款接口性能。这个时候我们就可以采用fast success的方式:当必要的校验和存储完成后,立即返回success,同时告诉调用方一个中间态“付款中”。而后调用银行接口,当获得支付结果后再调用上游系统的回调接口返回付款的最终结果“成果”or“失败”。这样就可以异步执行付款过程,提升付款接口效率。当然,为了防止多业务方接入的时候回调接口不统一,可以把结果抛进kafka,让调用方监听自己的结果。
结语
本文是笔者对工作中遇到的性能优化问题的一个简单的总结,可能有不完备的地方,欢迎大家讨论交流。同时,希望大家评论、点赞、转发!