如何解决微服务中数据一致性问题?
大家好,我是飘渺。
在我们曾经设计的一个供应链系统中,存在商品、销售订单、采购这三个服务,它们的主数据的部分结构如下所示:
商品:

订单和子订单

采购单和子订单

大家好,我是飘渺。
在我们曾经设计的一个供应链系统中,存在商品、销售订单、采购这三个服务,它们的主数据的部分结构如下所示:
商品:
订单和子订单
采购单和子订单
今天我们来讨论如何在项目开发中优雅地使用RocketMQ。本文分为三部分,第一部分实现SpringBoot与RocketMQ的整合,第二部分解决在使用RocketMQ过程中可能遇到的一些问题并解决他们,第三部分介绍如何封装RocketMQ以便更好地使用。
在SpringBoot中集成RocketMQ,只需要简单四步:
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-spring-boot-starter</artifactId>
</dependency>研发工程师的职业成长路线,基本是初级研发工程师,进阶为中高级研发工程师,提升至架构师,然后再寻求更高的突破。这直接说明我们认同架构师的价值,想要努力成为架构师。虽然目标很明确,但我调研后发现,大多数研发工程师把“成为架构师”当作目标,但却没找到方法。
因为在工作中,不是每一个研发都有机会参与架构设计;很多公司也不会主动去培养你成为架构师。所以,有很多职场人在一家公司工作三年或五年之后并没有多大的提升。
而很多的架构师都是研发自己在机遇巧合下,遇到大项目、参与其中、趟了坑、解决了问题,最终形成自己的知识体系和解决问题的能力之后才成长起来的。那么如果没有这些条件,你还有没有途径成为一名架构师呢?
当然有,在我看来,你要先掌握架构师的知识体系,然后再通过实践进行检验,这样才能逐步成长为一名架构师。
很早以前,我曾写过两篇介绍如何在SpringBoot中使用Guava和Redis实现接口限流的文章。具体包括:
现在,一个问题摆在我们面前:如何将这两种限流机制整合到同一个组件中,以便用户随时切换呢?
显然,我们需要定义一个通用的限流组件,将其引入到业务中,并支持通过配置文件自由切换不同的限流机制。举例而言,当使用limit.type=redis时,启用Redis分布式限流组件,当使用limit.type=local时,启用Guava限流组件。这种自由切换机制能够为用户提供更大的灵活性和可维护性。
接下来,让我们开始动手实现吧!
大家好呀,我是飘渺。
现如今市面上注册中心的轮子很多,我实际使用过的就有三款:Eureka、Gsched、Nacos,由于当前参与 Nacos 集群的维护和开发工作,期间也参与了 Nacos 社区的一些开发和 Bug Fix 工作,过程中对 Nacos 原理有了一定的积累,今天给大家分享一下 Nacos 动态服务发现的原理。
不 BB,上文章目录:
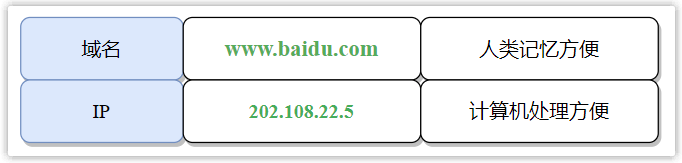
在日常上网过程中,出于好记的原因,人们更喜欢在浏览器中输入网站的域名,而不是 IP 地址。比如想要访问百度,则会输入 www.baidu.com,而不是 202.108.22.5(或者百度网站的其他 IP)。
然而计算机网络通信中所识别的标识并不是域名,而是 IP 地址,因为其可以提供主机在互联网中的位置信息,而且是定长的,路由器等设备更容易处理。
对于互联网来说,只要你系统的接口暴露在外网,就避免不了接口安全问题。 如果你的接口在外网裸奔,只要让黑客知道接口的地址和参数就可以调用,那简直就是灾难。
举个例子:你的网站用户注册的时候,需要填写手机号,发送手机验证码,如果这个发送验证码的接口没有经过特殊安全处理,那这个短信接口早就被人盗刷不知道浪费多少钱了。
那如何保证接口安全呢?
一般来说,暴露在外网的api接口需要做到防篡改和防重放才能称之为安全的接口。
问各位小可爱一个问题:MySQL 中 B 树和 B+ 树的区别?
请自己先思考5秒钟,看看是否已经了然如胸?

好啦,时间到了!
B 树和 B+ 树是两种数据结构,构建了磁盘中的高速索引结构,因此不仅 MySQL 在用,MongoDB、Oracle 等也在用,基本属于数据库的标配常规操作。
数据库要经常和磁盘与内存打交道,为了提升性能,通常需要自己去构建类似文件系统的结构。今天主要来看看数据库是如何利用磁盘空间设计索引的?