如何理解BFF架构?
在我们之前设计的一个供应链系统中,它包含了商品、销售订单、加盟商、门店运营、门店工单等服务,涉及了各种用户角色,比如总部商品管理、总部门店管理、加盟商员工、门店人员等,而且每个部门的角色还会进行细分。而且这个系统中还包含了两个客户端 App:一个面向客户,另一个面向公司员工和加盟商。
此时,整个供应链系统的架构如下图所示:
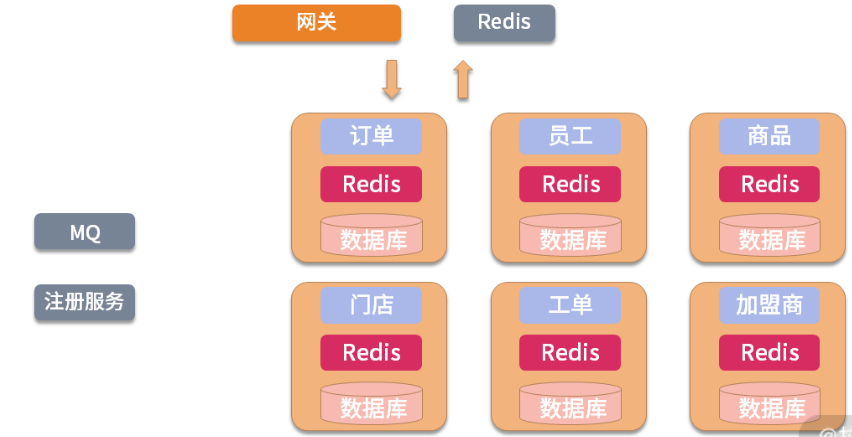
上图中的网关层主要负责路由、认证、监控、限流熔断等工作。
路由: 所有的请求都需要通过网关层进行处理,网关层再根据 URI 将请求指向对应的后台服务,如果同一个服务存在多个服务器节点,网关层还将承担负载均衡的工作。
认证: 对所有的请求进行集中认证鉴权。
监控: 记录所有的 API 请求数据,API 管理系统能对 API 调用实现管理和性能监控。
限流熔断: 流量过大时,我们可以在网关层实现限流。如果后台服务响应延时或故障,我们可以主动在调用端的上游服务做熔断,以此保护后端服务资源,同时不影响用户体验。
此时,我们的架构看起来是不是挺完美?且市面上标准的 Spring Cloud 架构都是这样做的。不过,这个架构会出现一些问题,下面我们先通过几个例子来看看。
案例一:
在这个供应链系统中,很多界面都需要显示多个服务数据,比如在一个 App 首页中,针对门店运营人员,需要显示工单数量、最近的工单、销售订单数据、最近待处理的订单、低于库存安全值的商品等信息。
此时第一个问题来了,在接口设计过程中,我们经常纠结将两个客户端 App 调用的接口存放在哪个服务中?以至于决策效率低下,而且还会出现职责划分不统一的情况。
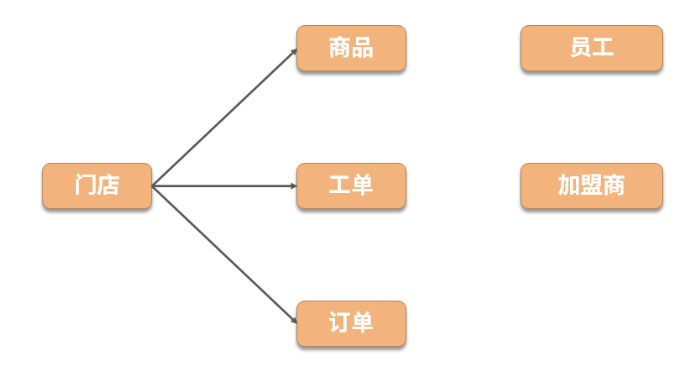
最终我们决定将第一个接口存放在门店服务中,此时调用关系如下图所示:
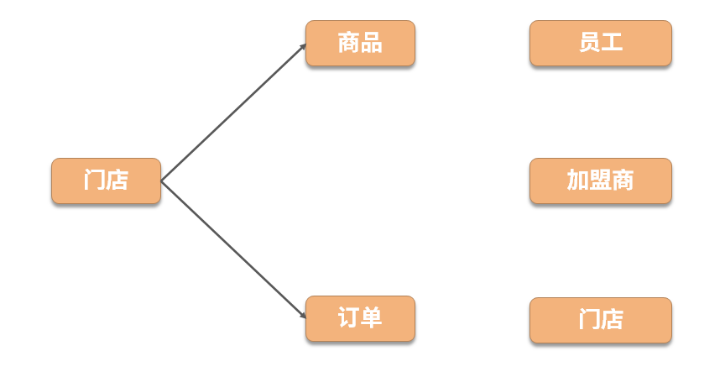
并将第二个接口存放在工单服务中,此时调用关系如下图所示:
案例二:
一个用户的提交操作常常需要修改多个服务数据,比如一个提交工单的操作,我们需要修改库存、销售订单状态、工单等数据。
此时第二个问题出现了,因为这样的需求非常多,所以服务经常被其他多个服务调来调去,导致服务之间的依赖非常混乱,最终服务调用关系如下图所示:
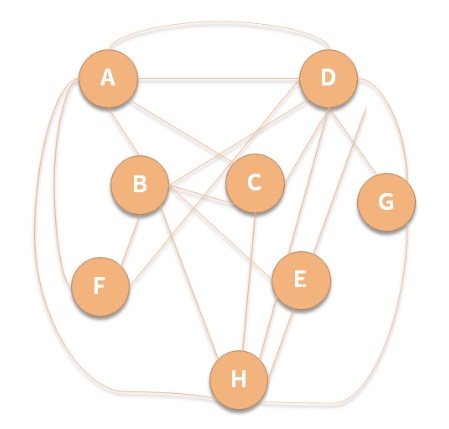
通过上图,我们发现服务间的依赖问题给技术迭代带来了地狱般的体验,关于这点我们已经在 15 讲中进行了细致讲解,这里就不过多赘述。
为了解决这 2 个问题,最终我们决定抽象一个 API 层。
API 层
一般来说,客户端的接口需要满足聚合、分布式调用、装饰这三种需求。
聚合:一个接口需要聚合多个后台服务返回的数据,并将数据返回给客户端。
分布式调用:一个接口可能需要依次调用多个后台服务,才能实现多个后台服务的数据修改。
装饰:一个接口需要重新装饰后台返回的数据,比如删除一些字段或者对某些字段进行封装,然后组成客户端需要的数据。
因此,我们决定在客户端与后台服务之间增加一个新的 API 层,专门用来满足上面的三点需求,此时整个架构如下图所示。
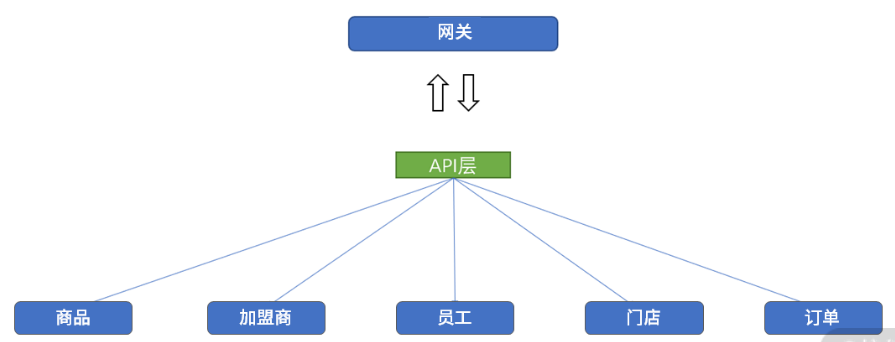
从图中我们发现,所有请求经过网关后,全部交由一个共用的 API 层进行处理,而该 API 层没有自己的数据库,它的主要职责是调用其他后台服务。
通过这样的设计方案后,以上两个问题就得到了很多地解决。
应该将某个接口放在哪个服务的纠结次数减少了: 如果是聚合、装饰、分布式的调用逻辑,我们直接把它们放在 API 层。如果是要落库或者查询数据库的逻辑,目标数据在哪个服务中,我们就把数据和逻辑放在哪个服务中。
后台服务之间的依赖也大幅减少了: 目前的依赖关系只有 API 层调用各个后台服务。
此时,我们的设计方案完美了吧?别高兴得太早,还会出现新的问题。
客户端适配问题
在这个供应链系统中,一系列的接口主要供各种客户端(比如 App、H5、PC 网页、小程序等)进行调用,此时的调用关系如下图所示:
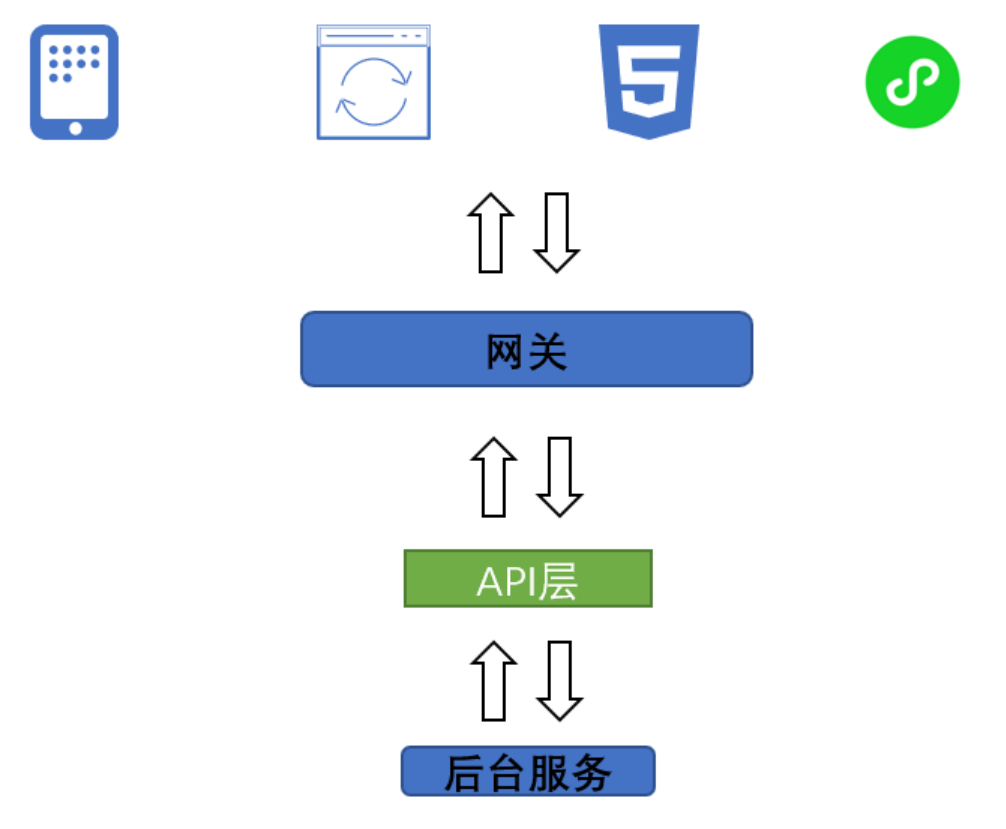
不过,这种设计方案会存在 3 个问题:
不同客户端的页面细节的需求可能不一样,比如 App 的功能比重大,就会要求页面中多放一些信息,而小程序的功能比重小,同样的页面就会要求少放一些信息,以至于后台服务中同一个 API 需要针对不同客户端实现不同适配;
客户端经常需要进行一些轻微的改动,比如增加一个字段/删除一个字段,此时我们必须采取数据最小化原则来缩减客户端接口的响应速度。而且,为了客户端这种细微而频繁的改动,后台服务经常需要同步发版;
结合 #1 和 #2 我们发现,在后台服务的发版过程中,常常需要综合考虑不同客户端的兼容问题,这无形中增加了 API 层为不同客户端做兼容的复杂度。
这时该如何解决呢?我们就可以考虑使用 BFF 了。
BFF(Backend for Front)
BFF 不是一个架构,而是一个设计模式,它的主要职责是为前端设计出优雅的后台服务,即一个 API。一般而言,每个客户端都有自己的 API 服务,此时整个架构如下图所示:
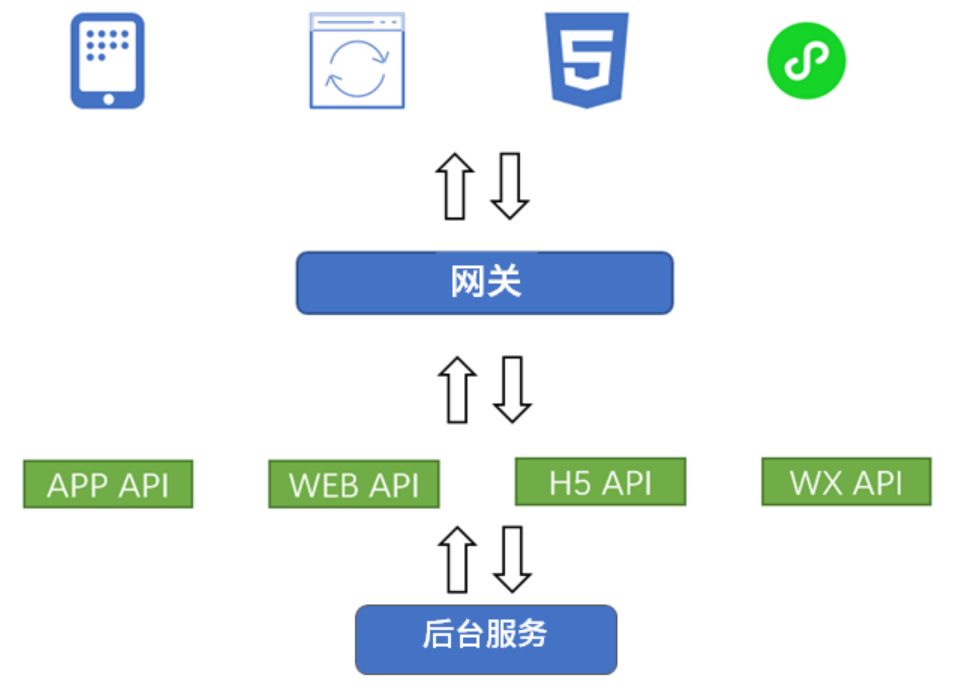
从上图可以看到:不同的客户端请求经过同一个网关后,它们都将分别重定向到为对应客户端设计的 API 服务中。因为每个 API 服务只能针对一种客户端,所以它们可以对特定的客户端进行专门优化。而去除了兼容逻辑的 API 显得更轻便,响应速度还比通用的 API 服务更快(因为它不需要判断不同客户端的逻辑)。
除此之外,每种客户端还可以实现自己发布,不需要再跟着其他客户端一起排期。
此时的方案挺完美了吧?还不完美,因为上面的方案属于一个通用架构。在实际业务中,我们还需要结合实际业务来定,下面我们深入说明一下实际业务需求。
前面我们列出了 5 种服务,实际上,整个供应链系统将近有 100 种服务。因为它是一个非常庞大的系统,且整个业务链条的所有工作都包含在这个系统中,比如新零售、供应链、财务、加盟商、售后、客服等,,这就需要几百号研发人员同时进行维护。
因为我们共同维护一个 App、PC 界面、新零售、售后、加盟商,还有各自的小程序和 H5,所以为了实现业务解耦和分开排期,每个部门需要各自维护自己的 API 服务,而且 App 与 PC 前端也需要根据部门实现组件化,此时的架构如下图所示。
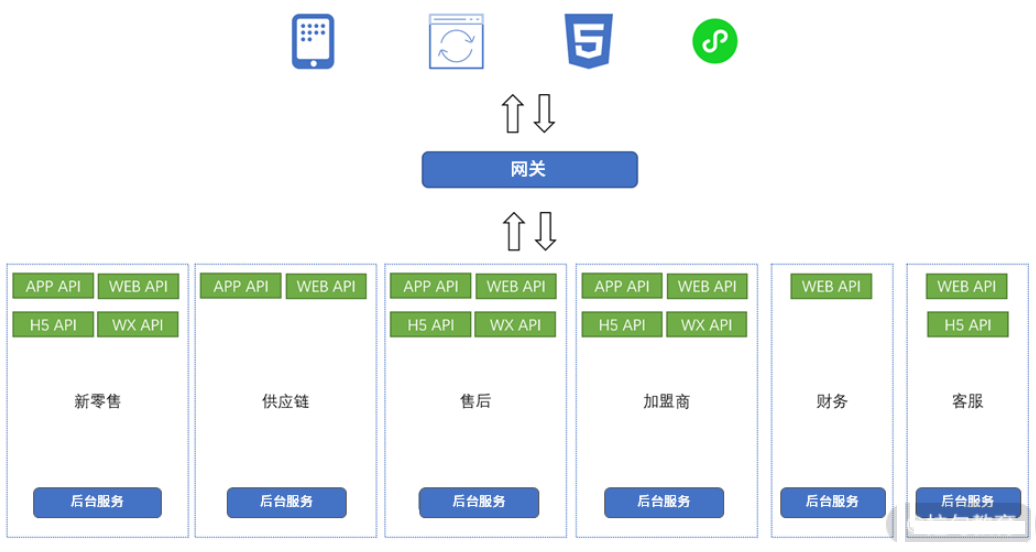
针对以上需求,我们如何在技术架构上进行实现呢?下面具体来看看。
技术架构上如何实现?
我们的整套架构还是基于 Spring Cloud 设计的,如下图所示:
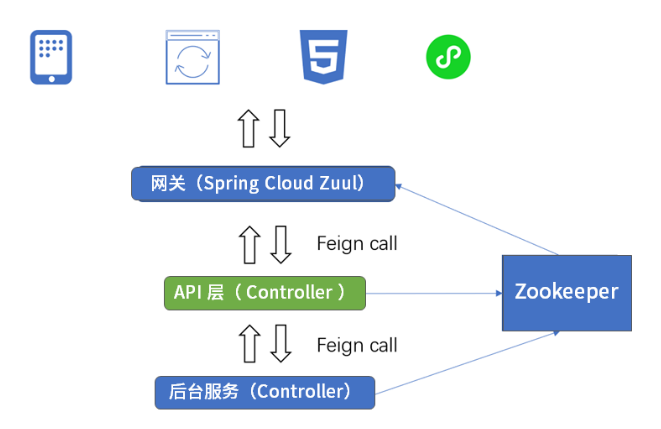
下面我们简单介绍下图中网关、API服务、后台服务的作用。
网关: 网关使用的是 Spring Cloud Zuul,Zuul 将拉取的注册存放在 ZooKeeper 的 API 服务中,然后通过 Feign 调用 API 服务。
API 服务: API 服务其实就是一个 Spring Web 服务,它没有自己的数据库,主要职责是聚合、分布式调用及装饰数据,并通过 Feign 调用后台服务。
后台服务: 后台服务其实也是一个 Spring Web 服务,它有自己的数据库和缓存。
此时的方案看着很完美了,不过它会出现 API 之间代码重复问题。此时我们该如何解决?且往下看。
如何解决 API 之间代码重复问题?
虽然 H5 与小程序的布局不同,但是页面中很多功能一致,也就是说重复的代码逻辑主要存在 PC API 和 App API 中。
然而,针对重复代码的问题,不同部门在设计时会呈现 3 种不同的逻辑:
某些部门将这些重复的代码存放在一个 JAR 中,让几个 API 服务实现共用;
某些部门将这些重复的代码抽取出来,然后存放在一个叫 CommonAPI 的独立 API 服务中,其他 API 服务直接调用这个 Common API 就行;
某些部门因为重复逻辑少,通过评估后,他们发现维护这些重复代码的成本小于维护 #1 中的 JAR 或者 #2 中的 CommonAPI 服务,所以会继续让这些重复代码存在。
假如某些 API 服务提供接口的出入参与后台服务的一致,此时该怎么办? 此时 API 服务的接口无须做任何事情,因为它只是一个简单的代理层。
于是,有同事提出:“每次一看到这些纯代理的 API 接口就不爽,我们能不能想办法把它们去掉。”办法倒是有几个,我们一起来看看。
网关直接绕过 API 服务调用后台服务,不过这样就会破坏分层,所以很快被否掉了。
在 API 服务层做一个拦截器,如果 URI 找不到对应 API 服务中的 controller mapping,就会直接通过 URI 找后台服务并进行调用。不过这种方式将大大增加系统的复杂度,出问题时调查起来更麻烦且收益不大。而写这些无脑代码不仅成本低,整体的接口列表还更可控。
综合考虑后,最终我们决定保留无脑的代码。
后台服务与 API 服务的开发团队如何进行分工?
最后我们是这样分工的:专门的 API 开发团队负责 API 服务,而后台服务需要根据领域再划分小组的职责。
这种划分方式的好处在于 API 团队能对所有服务有个整体认识,且不会出现后台服务划分不清晰、工作重复的情况。而坏处在于 API 团队整体业务逻辑偏简单,长久留不住人。